Web Scraping & Others
FastAPI CRUD APP DEMO
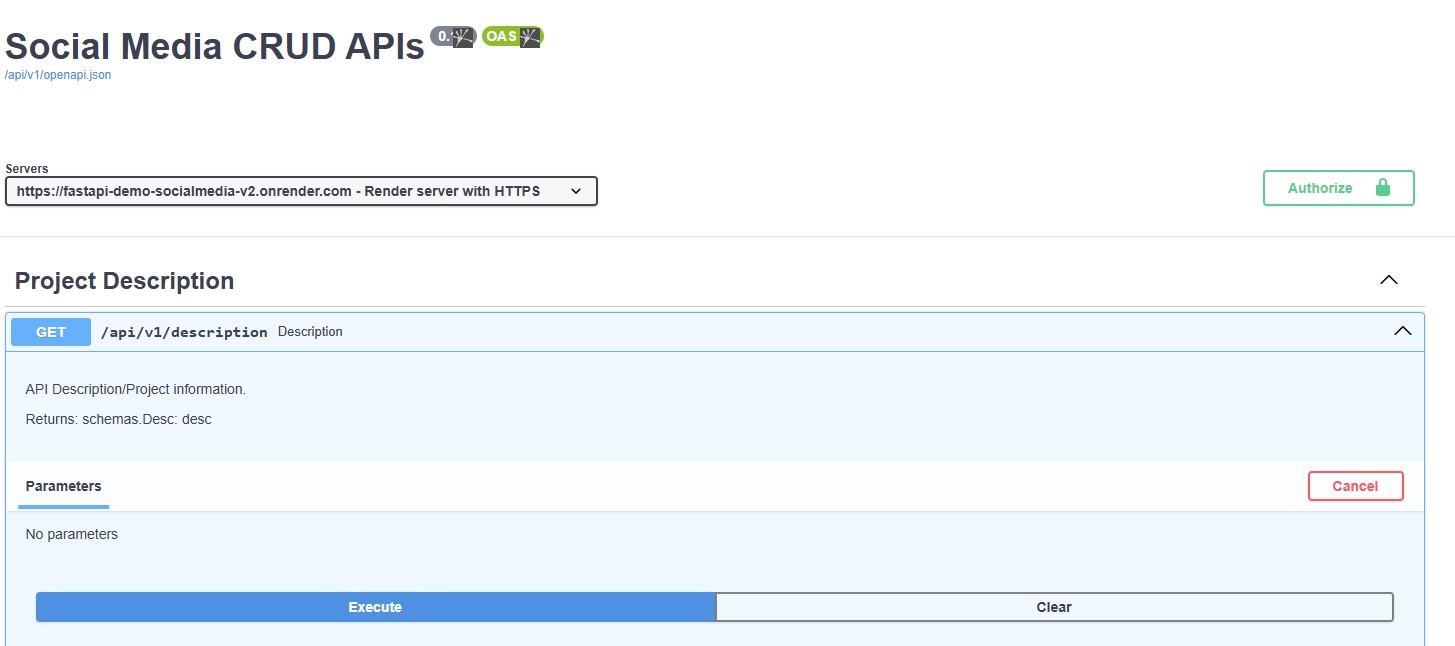
This repository demonstrates a CRUD-based social media API built with FastAPI. It showcases the implementation of modern RESTful API practices, focusing on user authentication, schema validation, and seamless integration with a PostgreSQL database.
The App is deployed on render.com
More on Github Github
Cropping Images Using Yolo v5
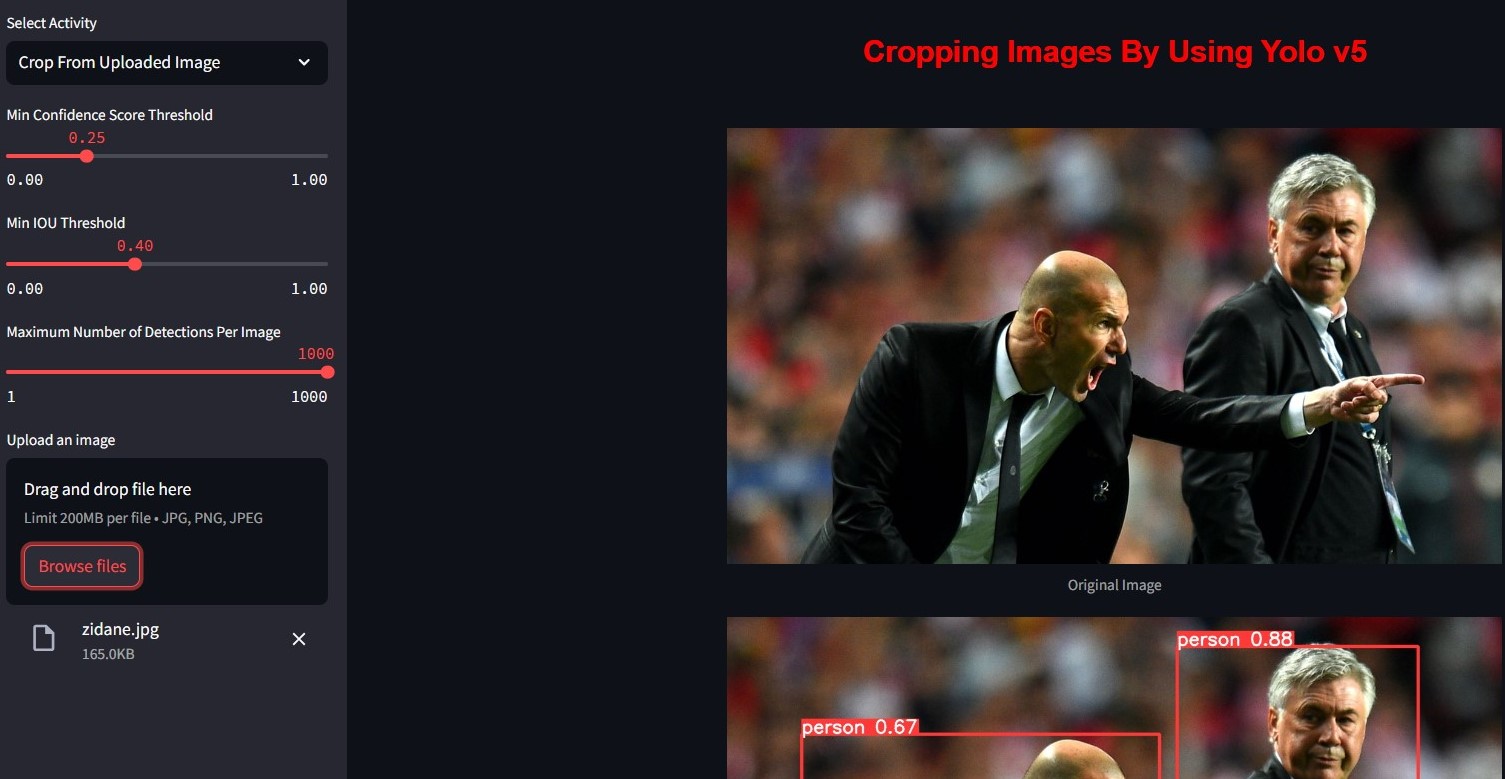
This Streamlit-based application utilizes YOLOv5, a popular object detection model, to perform multiple object detection on images. The detected objects can then be cropped and downloaded individually.
Object Detection Object Detection: Detect multiple objects in an uploaded image or from a provided URL.
Bounding Boxes Display bounding boxes around detected objects for visualization.
Cropping Crop the most visible object based on confidence scores and download the cropped image.
Flexibility Supports both local image upload and image URLs.
More on Github Github
Portfolio Website (Django)
The website you are viewing is based on Django and deployed on render.com
editorial was taken and some editions were done according to the needs.
More on Github Github
Web Scraping Carrefour's E-commerce Website
First file which is 1.Scraping-Carrefour_Product_Links.ipynb uses Selenium to scrape product links from the Carrefour Pakistan website for products.
It imports various libraries such as webdriver, keys, WebDriverWait, Select, expected_conditions, and tqdm. It then sets the URL of the webpage to be scraped and
downloads the webdriver to be used. The script then opens the URL in Chrome browser, maximizes it, and sleeps for 20 seconds. The script then attempts to click
on a "Next" button to scrape all the products on the webpage. It keeps clicking until it reaches the end of the webpage. Afterward, the script extracts all the
product links on the webpage and saves them in a CSV file.
2.Scraping-Carrefour_Products.ipynb The script reads URLs from a CSV file and visits each page to extract product data, including title, category, price,
description, and images. It then writes this data to another CSV file. If the data is not found, it writes the product name to a separate CSV file. The script also defines
a function to write headers to the output CSV file and opens two CSV files - one for storing scraped data and one for storing data not found. It then reads the URLs
from the input CSV file, opens each URL in turn, and extracts the required data using Selenium's find_element_by_xpath and find_elements_by_class_name methods. Finally,
it writes the extracted data to the output CSV file and saves any data not found to a separate file.
3.Saving_Product_Images.ipynb The code is for scraping product images from URLs in an Excel file using Python's BeautifulSoup, requests, urllib, tqdm,
pandas, and csv libraries. The program reads the Excel file with image links, saves the images as jpeg files, and stores them in a specific folder. It uses a
user-agent header to avoid being blocked and a try-except block to handle errors. The progress is monitored using the tqdm library.
4.Price_Extraction.ipynb The program reads URLs from the input CSV file and iterates through each URL to scrape the product title and price data
It then writes the scraped data to the output CSV file. If the data is not found, it writes the URL to another CSV file. The program closes the browser instance after scraping each URL.
More on Github Github
More Exercise on Web Scraping
Scraping E-Commerce Website Github
Scraping Real State Website Exercise Github
Weather Forecast
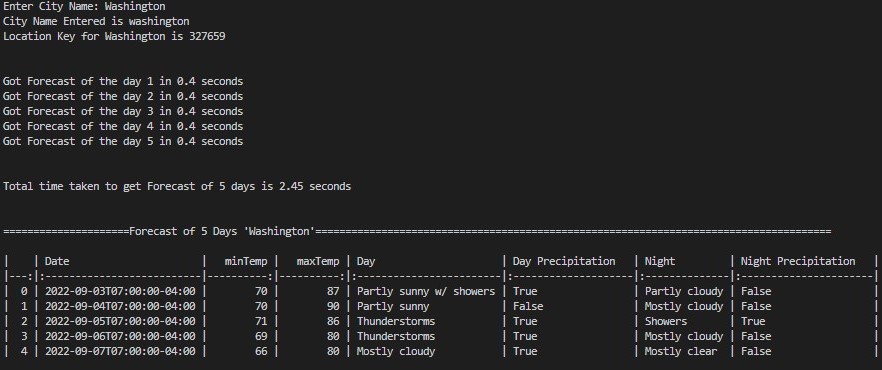
This Python code includes two functions, "citySearch" and "forecastFor5Days", that use the "requests" and "json" modules to make HTTP GET requests and handle JSON responses.
The "citySearch" function takes a URL and a payload, sends an HTTP GET request to the URL with the given payload, and returns a JSON object if the response is successful and contains data. If the response code is 200 but the response text is 'null', the function prints "City Not Found" and returns None. If the response code is anything other than 200, the function prints the status code and returns None.
The "forecastFor5Days" function also takes a URL and a payload, sends an HTTP GET request to the URL with the given payload, and returns a pandas DataFrame containing forecast data for the next five days if the response is successful and contains data. If the response code is 200 but the response text is 'null', the function prints "Not Found" and returns None. If the response code is anything other than 200, the function prints the status code and returns None.
The "forecastFor5Days" function extracts data from the JSON response and creates a dictionary for each day's forecast, which is appended to the "forecast_of_5_days" list. The function then sleeps for the amount of time it took for the previous request to complete, prints a message indicating that it has finished processing data for that day's forecast, and repeats the process until data for all five days has been processed. The list of forecast dictionaries is then converted into a pandas DataFrame and returned by the function.
More on Github Github
Image Utility: OpenCV with Streamlit
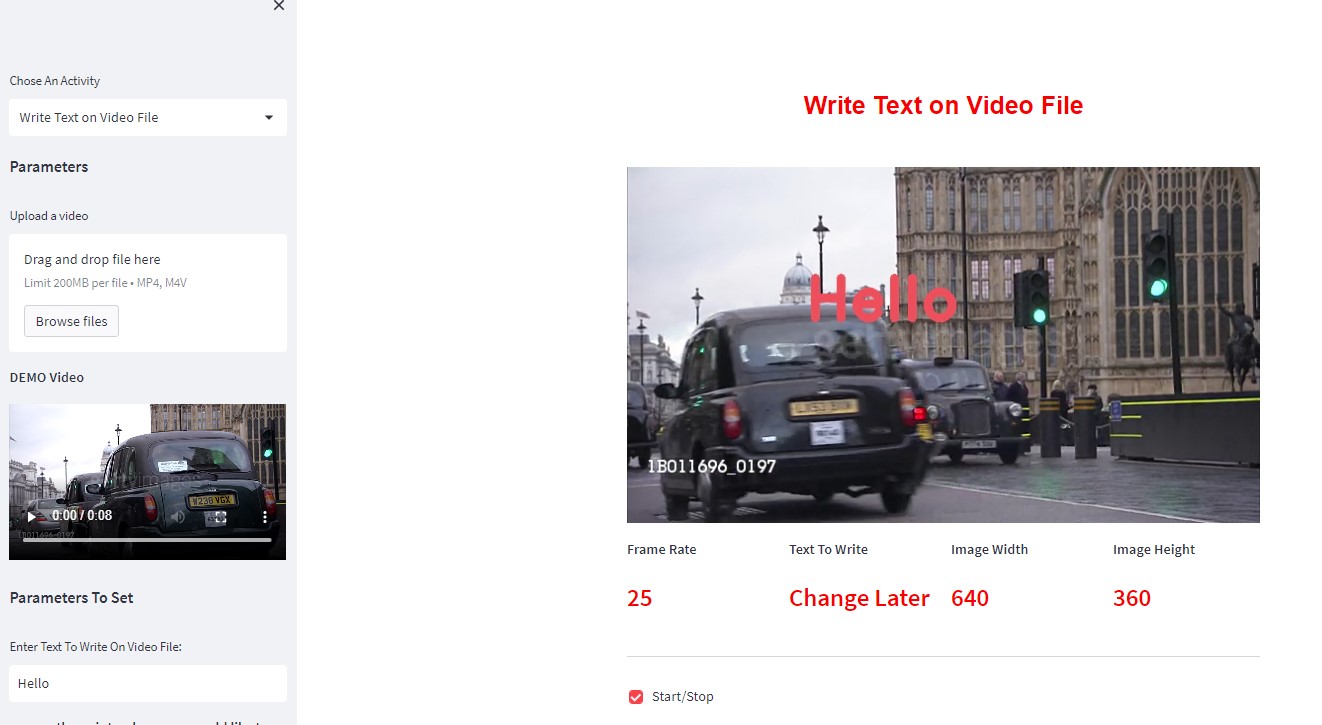
This is small image utility tool which is built with openCV and Streamlit. Following are the features it supports:
- resize images
- record video from local webcam
- write text on images/video files or live feed
- Take Pictures From Camera
- Blending Images of same/different sizes etc
More on Github Github
Convert DICOM Images to JPG and Resize
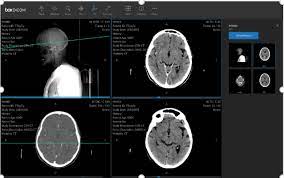
This Python code defines three functions read_xray, resize, and main. It also imports necessary modules including os, sys, numpy, pandas, pydicom, and Pillow (PIL).
read_xray function reads DICOM files from a given path and converts the pixel data to a human-friendly view if possible by applying VOI LUT (Value of Interest Lookup Table). The output image is normalized to a 0-255 scale, depending on the minimum and maximum values of the input array. If the image is monochrome1, the function inverts it. Finally, the function returns the output image array.
resize function takes an input image array, resizes it to a given width and height, and returns the output image. If keep_ratio is True, the function preserves the aspect ratio of the input image. If resample is given, it resamples the image using the specified method.
main function reads DICOM files from a given input path, resizes them to the given width and height, and saves them in PNG format in a new directory created for each split (train or test) in the input directory. It also extracts metadata including image id, dimensions (dim0, dim1), and split (train or test) and saves them in a CSV file named 'meta.csv' in a directory named 'check'. The directory path is hard-coded in the code.
The code is written to execute main function when executed as the main program using the if __name__ == "__main__": condition.
More on Github Github
Random Mouse Clicks on Screen
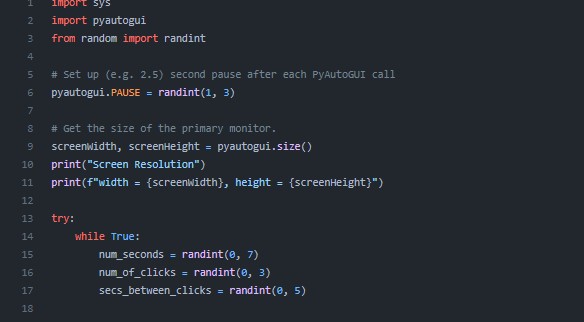
This is very small script, idea is to keep Colab Training Session Alive by random clicks on the screen
This Python code imports the sys and pyautogui modules, as well as the randint function from the random module. The code then sets a random pause time (between 1 and 3 seconds) for each PyAutoGUI call. The code then gets the size of the primary monitor and prints out its resolution. The code enters a while loop and generates random values for the number of seconds to move the mouse to a new position, the number of clicks to perform, and the number of seconds to wait between clicks. It also generates random coordinates to move the mouse and click, and gets the current position of the mouse. It then moves the mouse to the generated coordinates, and performs a click with the left mouse button, using the previously generated values for the number of clicks and wait time between clicks.
More on Github Github